Depth-First Traversal Orders in Binary Trees
Use Case:
Unlike common data structures such as arrays, stacks and linked lists, tree data structures can be traversed and values returned in multiple ways. One way in particular, known as depth-first search, can itself be manipulated into 3 different ways and that's what we're going to cover in this post.
It's important to note that, like arrays or lists, gathering and returning all values contained in tree data structure (binary tree or not) requires linear time - O(n) - as each node needs to be visited.
Also note that we'll be using the binary tree implementation that we covered in a previous post to build our tree.
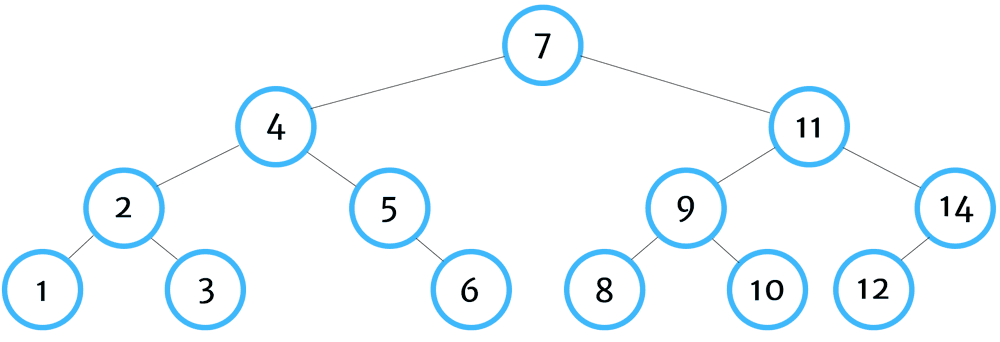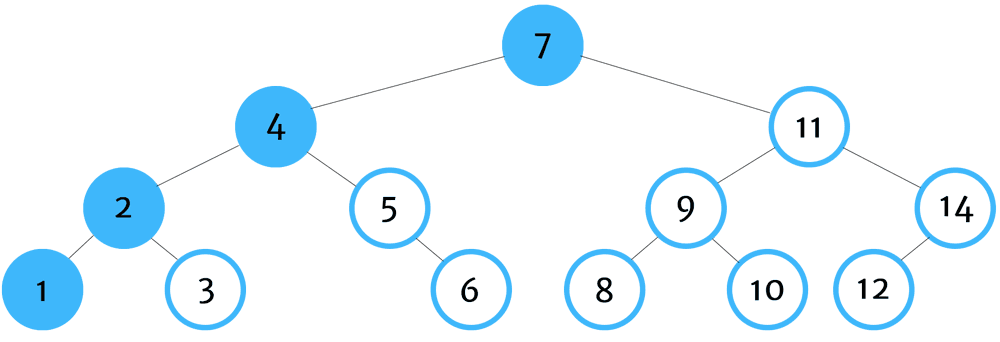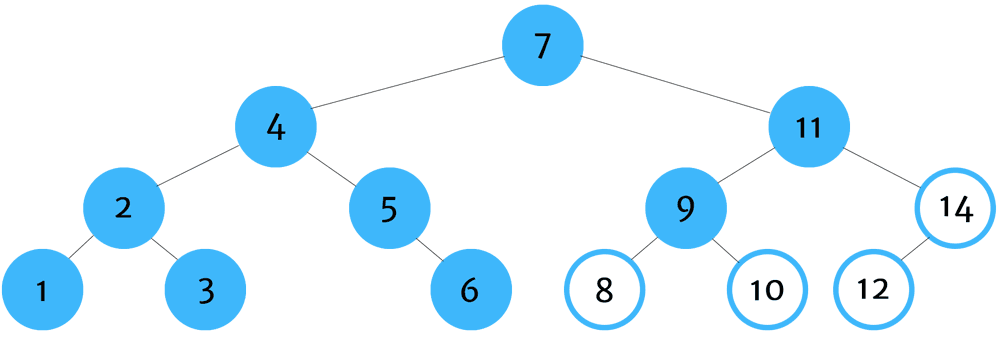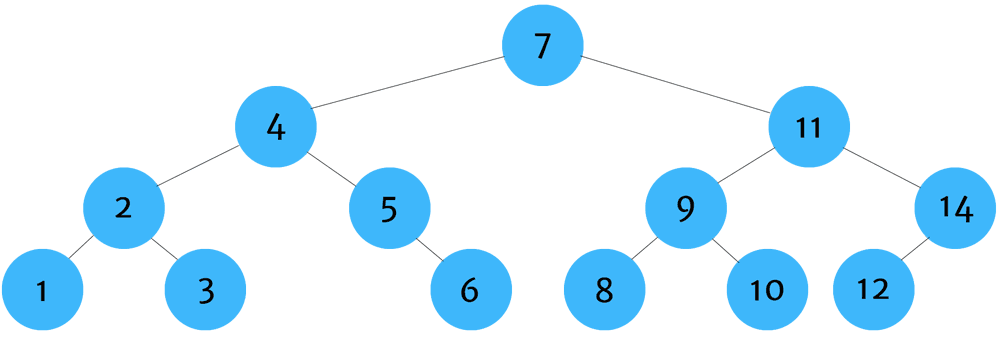
In-Order Traversal
In-order depth first tree traversal is one of the most commonly used traversal orders (particularly in ordered data structures such as binary trees) because they return nodes in order by their value.
Hey, Tyler here. I’m building Formyra, an AI-powered smart forms platform that helps businesses automate workflows, cut busywork, and turn form submissions into real growth.
If that sounds interesting, I’d love for you to check it out!
The algorithm starts by identifying the left-most leaf of the tree, returning that value, then traversing up to its parent, then to its parent's other child (if it exists), and then continuing to other sibling nodes of the parent.
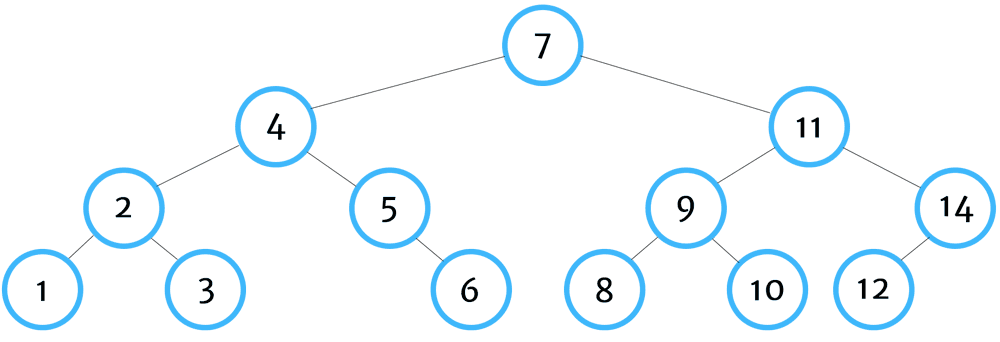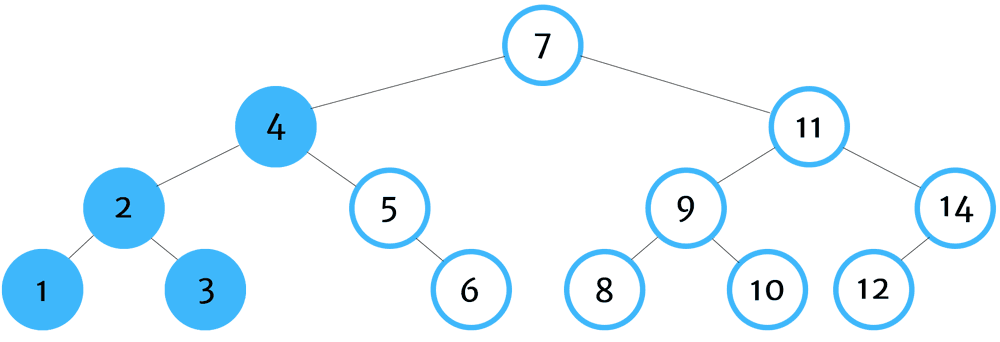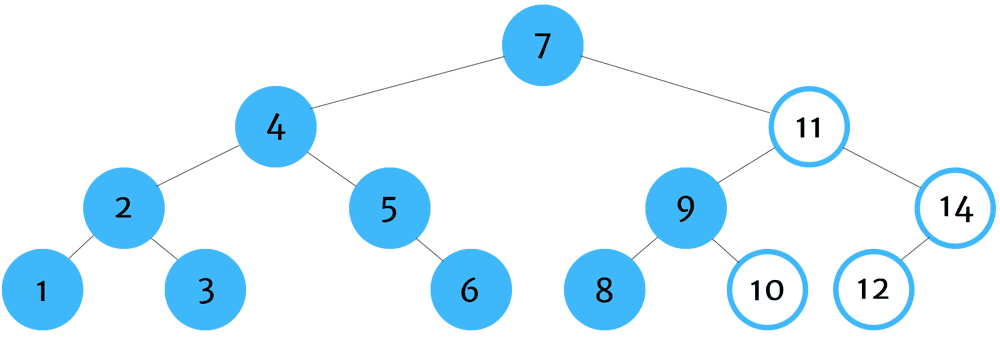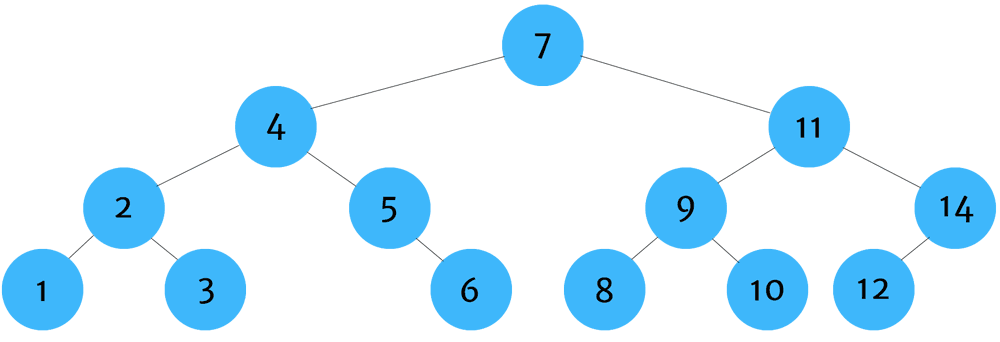
Here's the implementation:
JavaScript
Tree.prototype.inOrder = function(node) {
var node = (node) ? node : this.root
if (node.left) {
this.inOrder(node.left)
}
console.log(node.key)
if (node.right) {
this.inOrder(node.right)
}
}
tree.inOrder() // 1,2,3,4,5,6,7,8,9,10,11,12,14We'll start by creating a function called inOrder that belongs to our Tree class. The function will accept a node and then check if the contains a left child. If it does then it'll recurse the function on the left child. Then, it'll log the node's key to the console and check the right child.
You can remember in-order traversal by thinking - left, self, right.
Pre-Order Traversal
Pre-order traversal algorithms are useful when attempting to make a copy of a tree data structure - by recording the value of the parent node before collecing the children.
Here's the implementation:
JavaScript
Tree.prototype.preOrder = function(node) {
var node = (node) ? node : this.root
console.log(node.key)
if (node.left) {
this.preOrder(node.left)
}
if (node.right) {
this.preOrder(node.right)
}
}
tree.preOrder() // 7,4,3,1,3,5,6,11,9,8,10,14,12We'll create another function on our Tree class called preOrder. The only difference with this function is that we'll log the key of our node before scanning for children.
You can remember pre-order traversal by thinking - self, left, right.
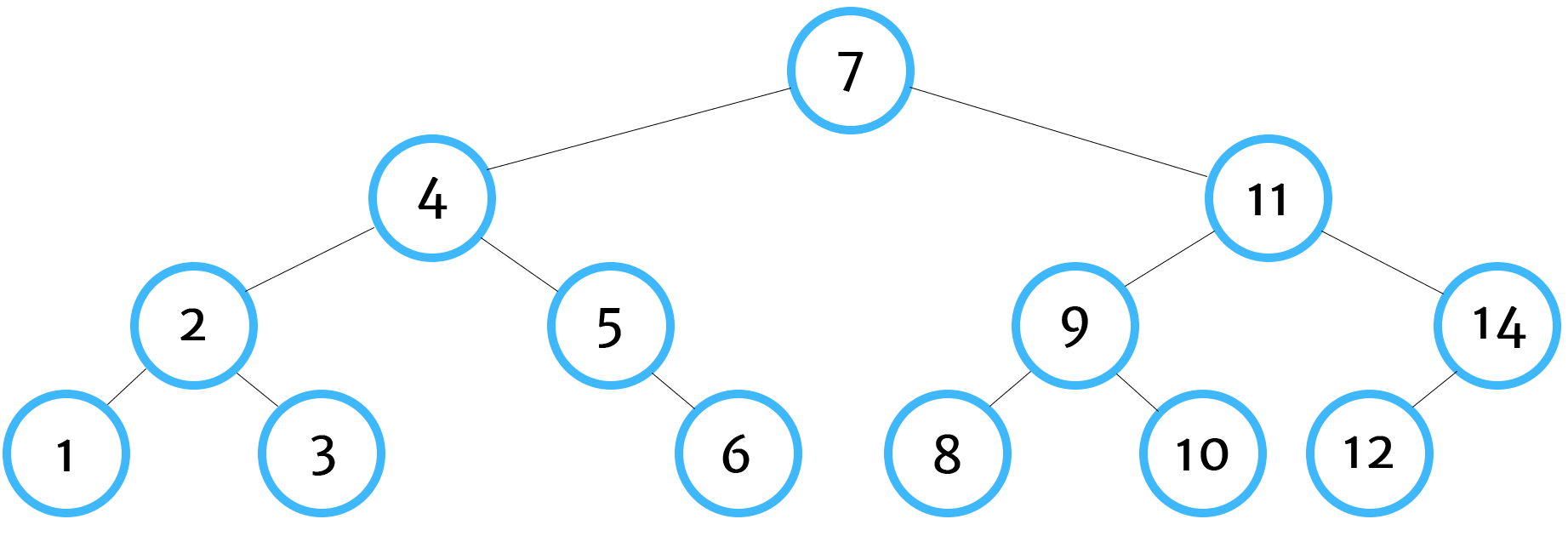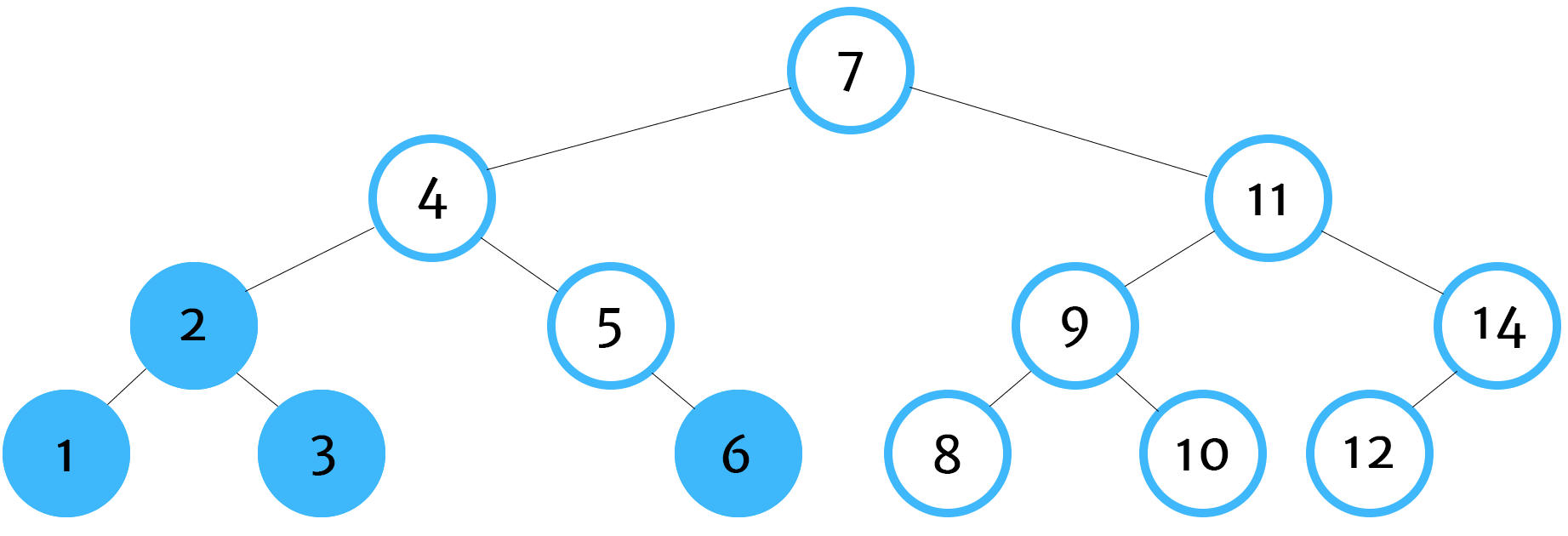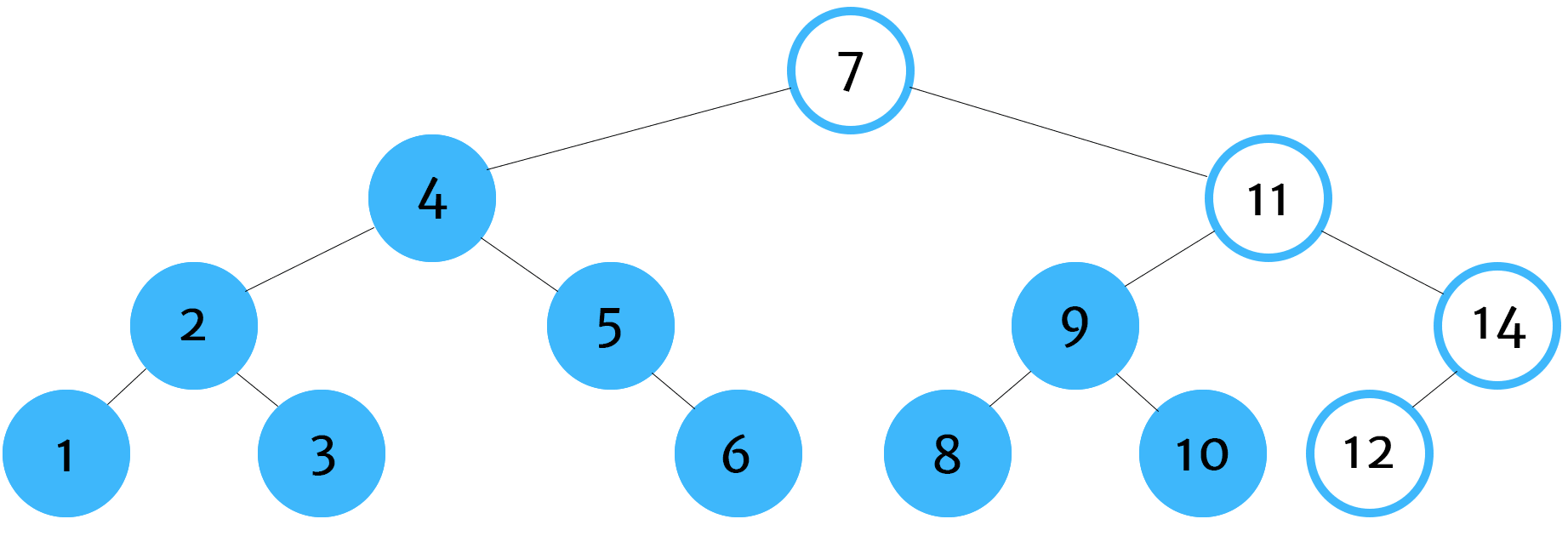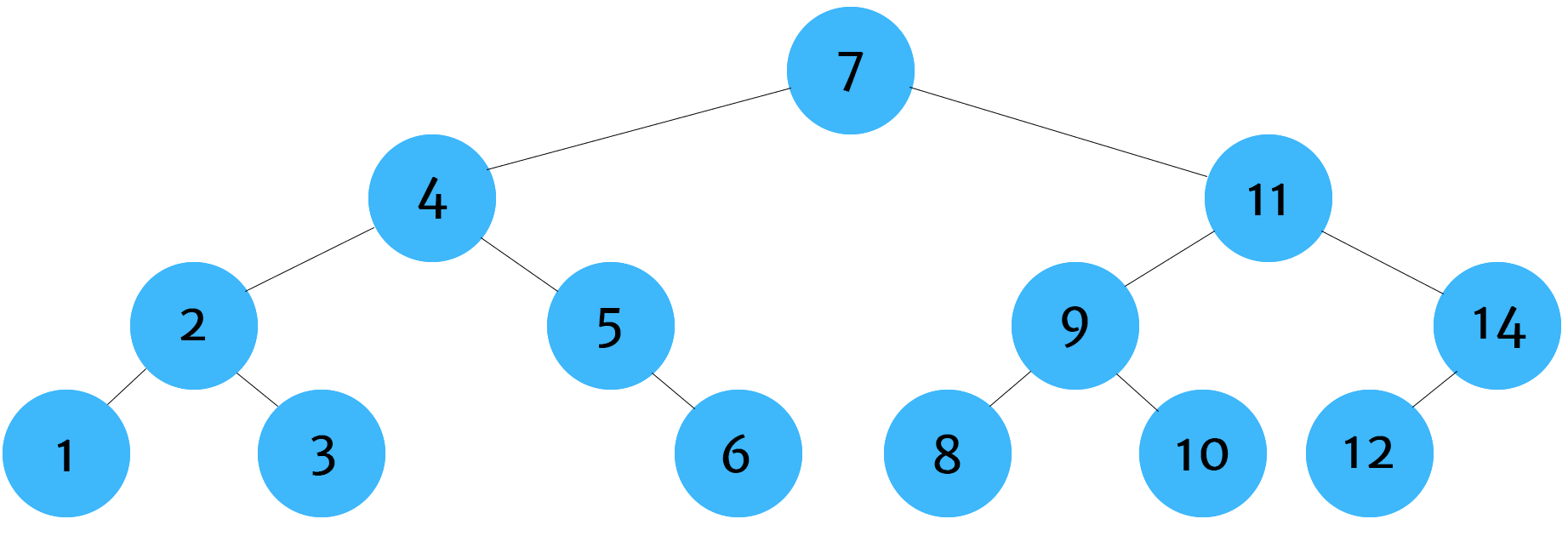
Post-Order Traversal
Post-order tree traversal is used most commonly when deleting tree data structures. The reason why this is important is because we need to find all children of a node before deleting the node itself. If we delete the node first, then we'll have no way of finding or identifying the children nodes. Once they are orphaned, we won't be able to locate and delete them which would cause an unnecessary strain on our system's memory.
Here's the implementation:
JavaScript
Tree.prototype.postOrder = function(node) {
var node = (node) ? node : this.root
if (node.left) {
this.postOrder(node.left)
}
if (node.right) {
this.postOrder(node.right)
}
console.log(node.key)
}
tree.postOrder() // 1,3,2,6,5,4,8,10,9,12,14,11,7In our postOrder function, we traverse the node's children before logging its key. Keep in mind that, in this example, we're just logging the key's value. However, in a real-world situation, we'd be performing some sort of action. For example, in post-order traversal the action would likely be the deletion of the node.
You can remember post-order traversal by thinking - left, right,self.